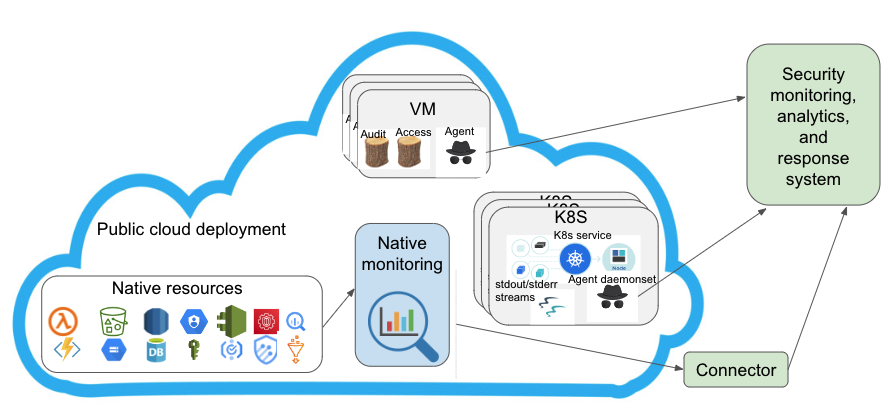
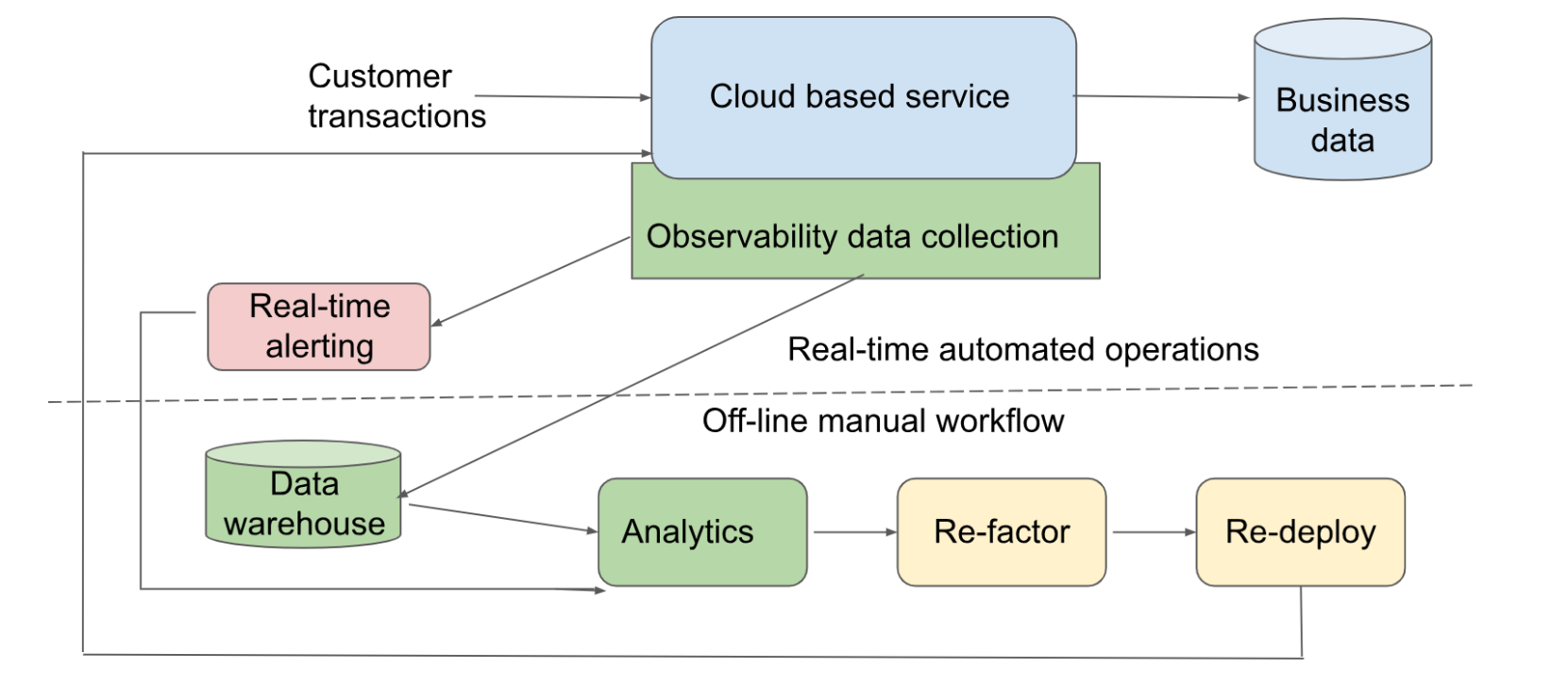
Observability is a critical component of any enterprise software-as-a-service (SaaS) application. These applications are deployed in public or private clouds. These deployments either rely on a cloud provider’s native observability solution or choose one of the third-party monitoring products. Either one of these two types of solutions typically work well for an early stage startup company.
At an early stage during an organization’s journey, operational needs to ensure that the business is always available through its web site and customers have a responsive usage experience is of critical importance. Any public cloud native monitoring solution as well as a third-party solution suffices to meet these goals. However, as an organization grows internally in size as well as externally in terms of customers or engagement, limitations of these solutions start becoming obvious. Some common ones include:
- Organization’s application logs or metrics are sourced through its unique instrumentation and collected (or streamed) in its own way, which is not supported by their selected observability solution.
- Organization’s observability data analytics use cases will start becoming highly customized to their core business logic and its adopted monitoring solution with generic use case support will not fit well.
- Observability data volume continues to grow exponentially and cost of selected solutions start becoming prohibitive. Development and operations often have to sacrifice observability to save the cost.
- Organization’s footprint expands to multiple public clouds. In such cases, native monitoring solutions become inadequate. In such cases, third-party monitoring solutions might help but they will suffer from all previous limitations.
Growing organization
Growing organizations typically deal with these limitations in one of two ways:
- Add multiple third-party solutions. This approach can take care of growing data sources, collection mechanisms, and analytics use cases. This approach will solve the immediate problem at the expense of additional cost. However, the underlying driver of growing data sources and use cases is still a factor and will kick in again sooner or later. In addition, multiple third-party solutions are not guaranteed to work well together, which will prevent data sharing among multiple internal user groups in a seamless fashion. At some stage, the organization will determine that this approach is not working and will move to the second possible solution that we discuss next
- evelop an in-house end-to-end observability platform. Since at this stage, an organization will have a good idea about its observability requirements, it can build a solution to address its current and future needs. While this is doable, it requires domain-specific expertise and cost. In addition, an end-to-end solution will be expected to meet various SLAs to ensure availability, security, and compliance to various standards. An organization will need to start and grow a dedicated monitoring team to deal with this continuously changing set of requirements.
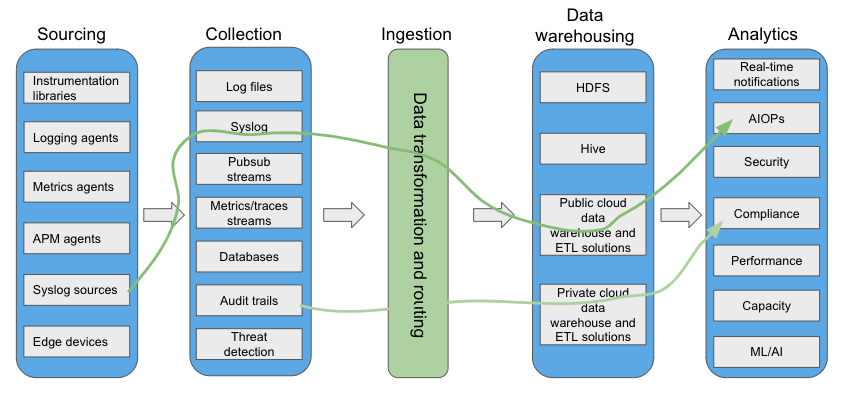
In order to understand the underlying factors that make observability a challenge for a growing organization, we can enumerate five stages from generation of observability data to its consumption: sourcing, collection, ingestion, warehousing, and analytics.
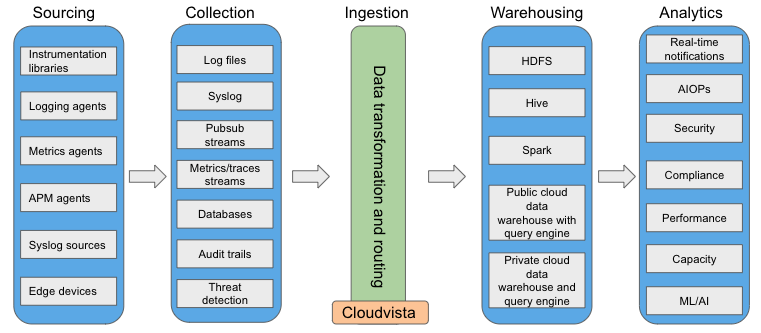
Number of combinations with ever increasing sources, collection mechanisms, data warehouses, and analytics is huge. It is not possible for a particular observability solution to cover all possible end-to-end paths and use cases. In-house purpose-built solutions simplify this combinatorial explosion by:
- Restricting some of the choices for collection mechanisms and data warehousing.
- Enforcing some data normalization to work with the selected data warehouse, which also provides a “single pane of glass” for all internal consumers of these data.
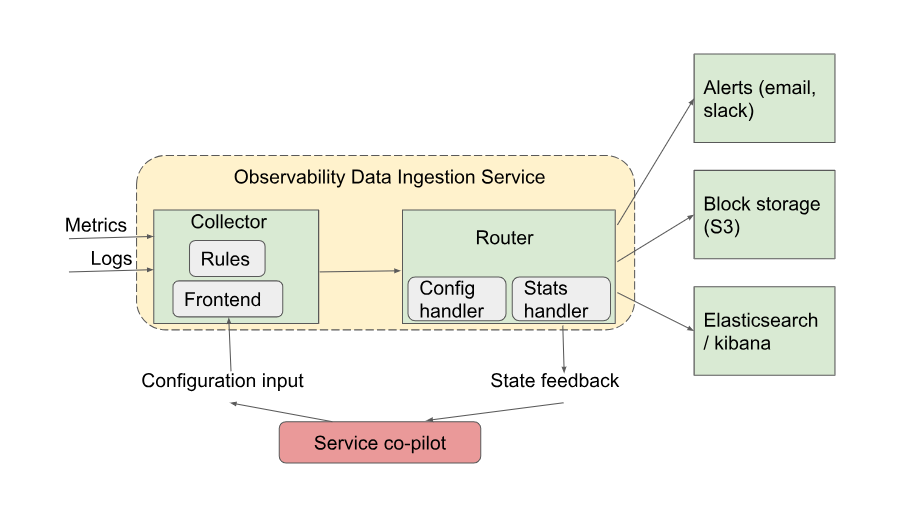
Ingestion is a critical component to glue various sources of data together through normalization. Once observability data is in a consistent format that includes adequate metadata to describe: (1) infrastructure provider details; (2) source application/service identifications; (3) organization-specific deployment details; (4) technology-specific deployment details; (5) collection specific details (timestamp, uid, etc.); and (6) payload type (e.g., syslog, metric, trace, etc.). A data warehouse can store these data using consistent representation. Organization’s internal users and analytics tools can use this consolidated format to perform their analytics and share the results through a “single pane of glass” visualization
Cloudvista partners with its customers to define and develop their custom ingestion layer to fulfill their current and future observability needs. We help our customers to leverage their current investment in native or third-party solutions as they transition to their own platform. We provide customized ingestion modules, develop data routing solutions, devise custom data retention policies, integrate with commercial or open source analytics solutions, and help maintain end-to-end operation of customer’s observability platform. Customers can achieve the goal of a purpose-built and future-proof observability pipeline with higher ROI compared to building and maintaining such a pipeline on their own.
For more information on how Cloudvista can enhance an organization’s ROI on observability, contact us at email : info@cloudvista.net